Social media is incredibly useful for maintaining friendships, reaching out and interacting with others. In particular, social media platforms like Twitter allow people to share and exchange ideas freely and easily.
In a previous blog post, we looked at how TWINT (a Python package which scrapes data from Twitter without using their official API) can be used to extract different types of interaction. Among these types of interaction include retweets.
Twitter’s retweet function is an incredibly important concept as it determines how trends form and how tweets go viral. Distributing content is as simple as a click of a button and social network analysis (SNA) is the solution for understanding what is going on.
In this blog post, we provide a very simple tutorial for performing network analysis of tweets by scraping a given topic on Twitter using a simple search query (e.g. #coffee). We then extract the retweets to form a retweet network using Python. But before we begin, it’s important to understand why social network analysis is important.
Why use social network analysis?
Social network analysis may sound like a boring research topic (for academics and researchers) but is incredibly important and useful to learn. Also, in my opinion, it’s a really interesting topic.
In the context of retweets, SNA helps us to get a bigger picture of what is going on at a much larger scale. Here are just a few reasons why SNA can help:
- They can be used to model the spread and tweets
- Help us understand how people interact with each other
- To understand influential users (e.g. who is retweeting the most)
- Find interesting relations between different user accounts.
Building Retweet Networks
Building, modelling and exporting retweet networks is incredibly easy thanks to three useful Python packages:
tweepy: Interacting with the Twitter API and collecting tweetspandas: Importing and exporting tabular datanetworkx: Generating and modelling interactions as graphs
To begin, start by importing the three packages and setting your API keys in the appropriate places shown below. Don’t know how to generate API keys from Twitter? Here is an easy-to-follow tutorial.
# Load in packages
import tweepy
import pandas as pd
import networkx as nx
# Set API keys
auth = tweepy.OAuthHandler('[TWITTER-APP-KEY]', '[TWITTER-APP-SECRET]')
auth.set_access_token('[TWITTER-OAUTH-TOKEN]', '[TWITTER_OAUTH-TOKEN-SECRET]')
api = tweepy.API(auth, wait_on_rate_limit=True)
...In order to the tweets, the search_tweets function is used to collect tweets which match the search query “#coffee”. The code below will retrieve as many tweets as possible by retrieving a chuck of 200 tweets at a time in an infinite loop until there is nothing left to scrape (hence the if len(ts) == 0 line). To avoid receiving duplicates, the max_id parameter is used to keep track of where we are. Tweets are then saved to a pandas dataframe using json_normalize .
...
# Set search term
query = "#coffee"
tweets = []
last_id = None
while True:
ts = api.search_tweets(q=query, count=200, max_id=last_id)
if len(ts) == 0:
break
tweets.extend([t._json for t in ts])
last_id = ts[-1].id - 1
df = pd.json_normalize(tweets)
...Now that we have got all the tweets, we need to filter for those that are retweets of another tweet. Conveniently, the Twitter API has a flag for this called retweeted_status.
When filtering for retweets, the column retweeted_status.user.screen_name must not be null or NaN. Note: the dots between the attribute in the column name are the result of pandas collapsing a nested JSON object into a single form. A NaN is the default value pandas used for handling values which aren’t set, in other words, retweet_status was not founding the tweet object, therefore it was not a retweet.
Filter for retweets can be arched with the following…
...
df = df[~df['retweeted_status.user.screen_name'].isnull()]
...Now that we’ve got the retweets, we can build the network!
networkx can be generated in graphs in a number of different ways. An overview can be found here. One of the easy techniques is to load it in from a pandas dataframe as an edge list using from_pandas_edgelist. Using this we can provide the dataframe and specify the source node, target node and network type (directed in this case as a user retweets from another user)
Creating the graph can be done with the following…
...
G = nx.from_pandas_edgelist(df, source='user.screen_name', target='retweeted_status.user.screen_name', create_using=nx.DiGraph)
...Additionally, we can include additional information such as timestamped edges to indicate when the interaction took place. This creates a temporal network.
...
G = nx.from_pandas_edgelist(df, source='user.screen_name', target='retweeted_status.user.screen_name', edge_attr='created_at', create_using=nx.MultiDiGraph)
With the newly created graph, we can check to see how many nodes are in the network.
>>> len(G.nodes())
9391This is just the tip of the iceberg and there is much more that we can do, thanks to networkx. A whole series on what you can do with networkx can be found here ranging from node profiling (such as in-degree centrality), community detection, core and link analysis.
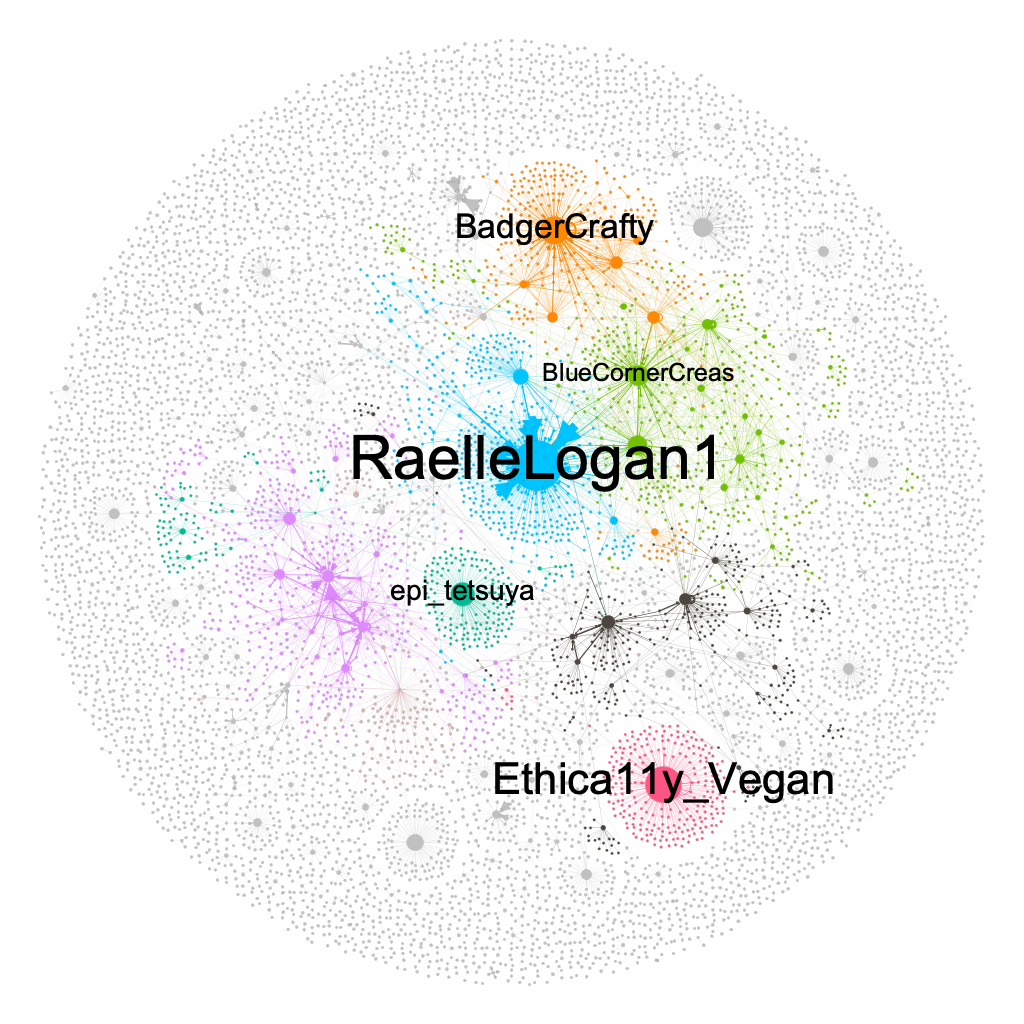
Visualisation

You can use whatever software you want (more on that here), in my case, I’m using Gephi – an ideal piece of software for Twitter network visualisations. Alternatively, you could use Graphviz or you could draw the network manually using the nx.draw method integrated into networkx which is based on matplotlib.
What’s next
Moving on from this, there is so much more you can do when it comes to analysing retweet networks and Twitter network analysis in Python more generally. Why not try and animate the network to see interactions evolve over time? Thanks to networkx, there are so many different ways you can analyse these networks, a few of which were mentioned in this post.
Overall, this post demonstrates how social networks can be built from Twitter network graphs in the form of retweet interactions.